Your AI agent can generate. It can even analyze. But can it actually learn? Most can't — and they all fail for the same reason. The answer starts with understanding why AI already works brilliantly in one domain: code.
Think about why LLMs are such remarkable collaborators on software. It's not just that they've been trained on GitHub. It's that code comes pre-packaged with its own context. Structure, dependencies, versions, and semantics are bundled together in a form both humans and machines can reliably interpret. An LLM reading a codebase doesn't just see text — it sees a self-describing artifact where everything needed to understand the system is right there.
Data doesn't work that way. Not yet.
Most analytical outputs, business records, and scientific datasets live in isolation — a CSV here, a results file there, context scattered across email threads and notebook comments. When an AI agent works with this data, it can execute on what it's given. But it can't accumulate knowledge across runs, because there's nowhere for that knowledge to reliably live.
That's the actual failure mode. Not model capability. Not prompt engineering. The absence of a persistent, structured, human-readable record of what the system knows and why — the same property that already makes code such a productive surface for AI.
We ran into this building AI-driven workflows at Quilt, a life sciences data management platform. In a series of working sessions with growth operator Kyle Eaton, we landed on a core insight:
If you want AI agents that compound their learning over time, you need a versioned, shared, human-readable context layer. Not a vector store. Not a prompt cache. A first-class data artifact that both systems and people can read, inspect, and trust — the way code already works.
For us, that context layer is Quilt Packages. But the architecture principles apply anywhere you're running multi-step AI workflows: outbound sales, experimental analysis, regulatory submissions, autonomous data pipelines.

The Problem: "Smart" Agents That Never Get Smarter
It's easy to demo an AI assistant that writes emails, summarizes research papers, or generates analysis code. It's much harder to build one that is measurably better this month than last month.
Why? The feedback loop breaks down fast:
- The model gets 90% of the output right, then drifts on tone or invents a line at the end.
- Performance signals are sparse and noisy.
- "Improvements" aren't traceable, so no one can tell what actually worked.
- Context from one run doesn't carry forward to the next.
This is true whether your agent is writing outreach emails, running QC checks on assay data, or triaging support tickets. The failure mode is universal: agents execute without accumulating knowledge.
We saw this firsthand. Our outbound agent could generate personalized three-touch email sequences from a HubSpot contact list. Generating content was never the problem. The problem was that draft number 200 was no smarter than draft number 1.

Why Code Succeeds Where Data Fails
The contrast is easiest to see in software development, where context is already structured for both humans and machines.
LLMs have become genuinely useful coding collaborators — not just autocomplete, but partners that can read a codebase, explain it, reason about it, and modify it alongside humans. That success isn't accidental, and it's not purely a function of training data volume. It's structural.
Code is packaged with its context. When an LLM reads a Python module, it gets the imports (what this depends on), the type annotations (what this expects and returns), the git history (how this evolved), and the surrounding tests (what this is supposed to do). Structure, dependencies, versions, and semantics are bundled together in a form both humans and machines can reliably interpret.
Data — most data — doesn't have this property. A CSV file is just values. A results file is just numbers. The context that makes those artifacts meaningful: what experiment produced this, what parameters were used, what version of the pipeline ran, what the analyst concluded — lives somewhere else, if it's captured at all.
So when an agent works with data, it can execute. It can transform values, run statistics, generate summaries. But it can't accumulate knowledge in a structured, inspectable way, because the data isn't packaged with the context that would make that knowledge durable.
Quilt Packages bring the packaging property of code to data. Every artifact — the raw data, the analysis, the conclusions, the hypotheses — versioned together as a single unit, with metadata, in a form both humans and machines can reliably read. The same structural property that makes AI effective with code, applied to the data your agents actually work with.
The Moment It Clicked: Packages as Persistent Context
Kyle's outbound agent had a built-in memory system from Agno, the agent framework we used. It stores memories as key-value pairs that the agent can read and write between sessions.
The natural move was to turn that on. But when we looked at what that actually meant, we hesitated. As I said to Kyle during one of our sessions:
"I think it makes more sense to keep the Quilt Packages as our memory. And then we can check it and version control it. If it goes into [framework] memory, all of a sudden that context is just kind of in a black box. It has access to it, but we can't read it."
This is the moment the whole architecture shifted. The question stopped being "how do we give this agent memory?" and became "how do we give this agent persistent context that we can also read, inspect, version, and share?"
Kyle's response landed the point: "I actually really like that. It's a cool use case for Quilt to say: this is our memory layer."
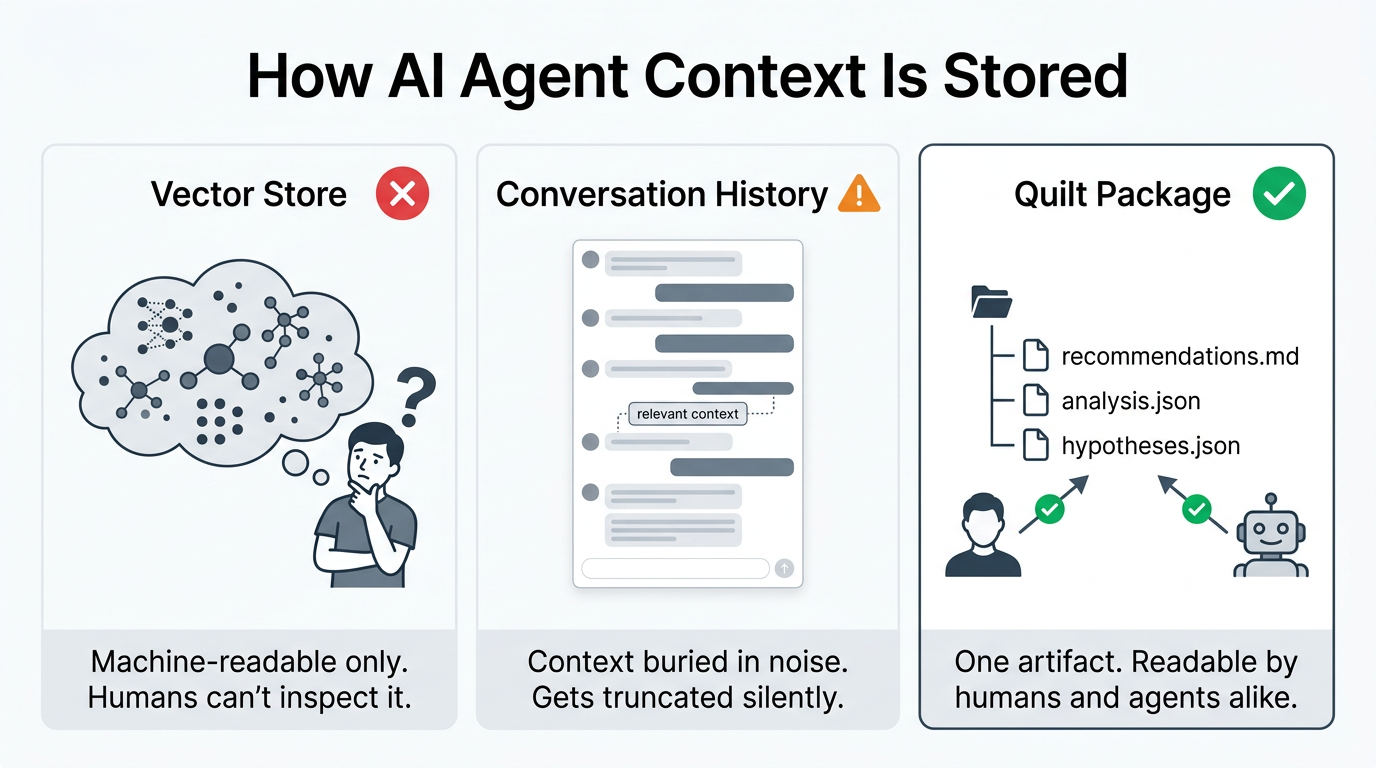
Why Your Agent's Context Must Be Human-Readable
This is the part most AI architecture discussions skip over, and it's the most important part.
Standard approaches optimize for machine retrieval. Vector stores embed knowledge as high-dimensional points that are semantically searchable but completely opaque to the people who need to trust the system. Conversation history keeps a rolling window of tokens that gets silently truncated as it grows. Framework-level memory stores structured data the agent can access, but it lives inside the agent's runtime, invisible to everyone else.
All of these patterns share the same flaw: they create an accountability gap.
In any high-stakes environment, whether that's sales strategy, scientific research, or regulatory compliance, the humans overseeing the system need to be able to answer three questions at any time:
- What does the agent currently "know"? What beliefs, recommendations, and strategies is it operating from right now?
- When did it learn that? What specific data or outcome caused this belief to form?
- Is it still right? Does this recommendation still hold given what we know today?
If the context layer is a vector store, you can't answer any of these questions without building specialized tooling to decode embeddings back into human language. If it's a conversation log, the context that matters is buried in thousands of tokens of noise. If it's framework memory, you need to go spelunking through an admin panel that wasn't designed for strategic review.
With a Quilt Package, you open recommendations.md and read it. It's a markdown file. Your product manager can read it. Your scientist can read it. Your CEO can read it. The agent can also read it, because markdown parses trivially into any LLM context window.
The same artifact serves both audiences without translation.
Kyle put it well in our follow-up session: "I can create all the HubSpot dashboards in the world, but the team is much less likely to look at those than they are a Quilt Package... you have no excuse to not have read them if they come over in your format of choice."
This isn't a nice-to-have. In regulated industries like life sciences, an agent making decisions based on opaque context is a compliance liability. In sales, an agent optimizing toward a strategy no one has vetted is a brand risk. Inspectable context isn't about transparency theater. It's about making the system actually trustworthy enough to delegate to.
Why Versioning Changes Everything
Making context human-readable solves the inspection problem. But versioning solves a different, equally critical problem: the ability to reason about change over time.
Consider what happens when your agent's performance degrades. With unversioned context, you're stuck. The state was overwritten. The previous version is gone. You can see that outputs got worse, but you can't trace it back to which specific change in the agent's knowledge caused the regression.
With versioned packages, every update creates a new, immutable revision. The previous state isn't gone. It's revision N-1, and you can diff it against revision N.
This gives you capabilities that are impossible with any other approach:
- Causal debugging. Performance dropped after revision 7? Diff revisions 6 and 7. See exactly which recommendation changed. Was it the shift from question-led subject lines to statement-led? Roll it back and test.
- Confidence over time. A recommendation that has persisted across 12 revisions of analysis, each confirming the same finding, carries more weight than one that appeared in the latest revision. Versioning gives you a natural measure of how battle-tested a piece of knowledge is.
- Safe experimentation. You can branch the package, let the agent try an experimental strategy for a cycle, and if it fails, revert to the last known-good revision without losing any data.
- Audit trail. For regulated industries, you can demonstrate exactly what the agent knew at any point in time, when it learned it, and what data supported the conclusion. This is the same standard we hold lab notebooks to, and it's the standard we should hold AI agent context to.
For scientists, this principle is intuitive. You wouldn't accept a lab notebook that erases previous entries. You wouldn't trust an experiment that can't be reproduced because the parameters were overwritten. Your AI agent's context should work the same way: append-only, fully traceable, diffable against any prior state.

The Package as Atomic Unit of Context
Here is the idea that ties it all together, and the reason Quilt Packages are uniquely suited to this problem.
A Quilt Package isn't just a file. It's a bundle of related artifacts, versioned together as a single unit, with metadata, stored on S3. When you update the analysis, the recommendations, and the hypotheses in the same revision, they're guaranteed to be consistent with each other. They moved together. They mean the same thing.
This makes the package the natural atomic unit of context for any system, human or machine, that needs to understand a body of knowledge.
Return to the code analogy for a moment. A well-structured software package — a Python library, a Node module, a Rust crate — is useful to AI precisely because it bundles everything needed to understand it: the source, the tests, the dependencies, the documentation, the version history. Remove any one of those layers and the LLM's ability to reason about it degrades. The bundle is the thing.
A Quilt Package works the same way for data. Think about what "context" means for an AI agent. It's not a single fact. It's a constellation of related information: performance data, strategic recommendations derived from that data, hypotheses being tested, constraints being observed. These things are meaningless in isolation. analysis.json without recommendations.md is just numbers. recommendations.md without hypotheses.json is just opinions without a test plan.
The package holds them together. When an agent reads a package, it gets the full picture in one operation. When a human browses a package, they see the same full picture. When the learning agent writes a new revision, all the artifacts update atomically, so there's never a moment where the analysis says one thing and the recommendations say another.
This is the same property that makes packages powerful for scientific data. A sequencing run isn't just a FASTQ file. It's the FASTQ, the sample manifest, the QC metrics, the instrument calibration data, and the analysis parameters, all versioned together. If you separate them, you lose the ability to reproduce the result. If you bundle them, the package becomes a self-contained unit of knowledge that any system, wet-lab scientist or autonomous pipeline, can pick up and understand.
For AI agents, the principle is identical. The package is a self-contained unit of knowledge that any system, human operator or downstream agent, can pick up and act on with confidence.
The Architecture: Learn, Store, Reinforce
With the context layer defined, the architecture falls out naturally. We split the workflow into two specialized agents:
Learning Agent
Pulls performance data (opens, clicks, replies, conversions in our case; could be assay results, pipeline metrics, or model accuracy in yours), evaluates outcomes against a composite score, and writes structured analysis to the package.
Reinforcer Agent
Reads the latest package revision, interprets the analysis and recommendations, proposes strategic changes for the next cycle, then drafts updated content or actions for human review.
The package between them contains:
analysis.json— raw performance data with scoring methodologyrecommendations.md— strategic guidance, written for humans, parseable by agentshypotheses.json— explicit experiments with current status and outcomesstrategy.json— active constraints, guardrails, and cadence rules
Kyle described the full loop: "Have [the learning agent] measure the performance of the outbound agent, and there's some sort of package in Quilt that it's filling with suggestions that the outbound agent goes and looks at and goes: okay, next batch, I'm going to do like this."
His next words: "That's full loop."
It is. And the loop compounds because every cycle's output becomes the next cycle's input, and the entire history is preserved in the package's revision log.

A Crucial Process Change: Separate Strategy from Execution
One of the biggest breakthroughs wasn't a model choice. It was workflow design.
At first, we asked one agent to do both strategy and content generation in a single pass. That created an all-or-nothing approval problem: accept everything or reject everything. If the strategy was good but one email was off, you couldn't approve the strategy without also approving the bad email.
So we decoupled it:
- Agent proposes a strategic direction for the next period (stored in the package).
- Human approves or revises the direction.
- Agent drafts individual outputs (emails, analyses, reports).
- Human approves or revises item by item.
That single change made the system dramatically more usable. The human stays in control of the "what" while delegating the "how."
This pattern works for any domain. A computational biology team could have an agent propose which analysis methods to apply to new sequencing data (strategy), get scientist approval, then execute each analysis (execution). The scientist retains control of the scientific judgment while the agent handles the computational labor.
This pattern works for any domain: keep human oversight on strategy ("what"), and let agents scale execution ("how").

Data Quality: The Real Bottleneck No One Wants to Talk About
Kyle raised a point in our very first session that reframed our entire priority stack: agent performance is capped by upstream data quality.
"Before we run this agent, we need to set up some sort of cadence of data enrichment, because there's a lot of job titles missing. Without job titles, we can't set the persona, and the persona is set automatically by HubSpot."
This is obvious in retrospect but easy to overlook when you're focused on prompt engineering. The agent can't write a personalized email to a "Technical Champion" if the CRM doesn't know that person's job title. The agent can't segment by company stage if the company data is stale. The model is doing its best with garbage inputs, and no amount of prompt refinement can fix that.
In practical terms:
- Clean, structured metadata matters more than clever prompting.
- Consistent naming and annotation matters more than model selection.
- A data enrichment pipeline (we used Clay) isn't a nice-to-have; it's a prerequisite for agent performance.
- The AI can surface data quality issues, but it can't rescue fundamentally broken upstream data.
This generalizes to every domain. In life sciences, if your sample metadata is inconsistent, your analysis agent draws bad conclusions. If your file naming conventions are chaos, your pipeline agent can't reliably find what it needs. Quilt Packages help by introducing logical namespaces over S3-backed data, so teams can rationalize legacy structures without expensive object-level renames. Data packaging — organizing data into clean, metadata-rich, versioned bundles — is what makes agents effective. It's not just a storage choice. It's the foundation that agent performance is built on.
Explicit Hypotheses Over Vague Optimization
The final piece of the architecture: don't just measure outputs. Track explicit hypotheses.
In our outbound system, that looked like:
- Does a threaded email sequence outperform standalone sends?
- Does referencing a specific case study increase reply rates?
- Does a question-led subject line beat a statement?
In a scientific workflow, the same principle applies:
- Does normalizing by batch before analysis reduce variance?
- Does a specific QC threshold improve downstream model accuracy?
- Does including instrument calibration metadata change sample flagging rates?
When hypotheses are explicit and stored in the package as structured data (hypotheses.json), analysis sharpens. Instead of "this batch performed better," the learning agent can identify exactly which assumption held and the reinforcer can incorporate proven approaches into the next cycle with confidence.
Over time, the hypotheses file becomes a running record of what the team and the system have tested. New team members, or new agents, can read the history and avoid re-running experiments that have already been resolved. The knowledge compounds.
The Bigger Picture
The most useful frame from this entire build is simple:
Treat your AI agent like a new teammate.
If you'd onboard a human with better documentation, cleaner data, clearer hypotheses, and tighter review loops, do the same for the agent.
The payoff isn't just better individual outputs. It's a compounding system for learning. Every cycle makes the next one smarter, and every revision is traceable, shareable, and human-readable.
Whether you're running outbound campaigns, analyzing experimental data, managing regulatory submissions, or building autonomous data pipelines, the architecture is the same:
- A versioned context layer that both humans and machines can read, inspect, and trust.
- Human-readable artifacts that close the accountability gap between what the agent knows and what the team can verify.
- Atomic packaging so context is always complete, consistent, and portable — the same structural property that already makes AI effective with code.
- Explicit hypotheses that turn vague improvement into measurable, reproducible progress.
- Human-in-the-loop review at the strategy level, not just the output level.
The Quilt Package is the unit that makes all of this possible. It's not just a container for files. It's an interchangeable unit of context and knowledge, letting both humans and AI systems read the same critical information, at the same time, with the same fidelity — the way code already works for software teams, now extended to every domain where data is the foundation.
That's what we built. And it compounds.
Quilt is a life sciences data management platform that organizes data into packages both scientists and AI systems can understand. Try Quilt Open or learn more.
Comments